
Introducción a los Modelos Generativos
 |
|---|
| Figura 1. La evolución de los rostros sintéticos generados por los modelos GAN. De izquierda a derecha: GANs, DCGANs, CoGANs y ProgressiveGANs. Imagen extraída de Brundage et al. |
Una red neuronal profunda puede operarar con datos de alta dimensionalidad, como imágenes, texto, sonido, video, etc. Una gran parte de estos modelos son discriminativos, reciben como entrada un dato de alta dimensionalidad, procesan la información y retornan una salida semánticamente significativa—una etiqueta o un escalar. Por otro lado, en un modelo generativo, el proceso es inverso—el dato complejo es la salida.
Debido a que la tarea de un modelo generativo es la de generar datos, estos tienen una tarea más compleja que los modelos discriminativos. Sin embargo, un modelo generativo también puede realizar las tareas de un modelo discriminativo.
Dado los datos de entrada $x$ y sus respectivas etiquetas $y$, un modelo discriminativo aprende directamente la probabilidad condicional $p(y|x)$. Mientras que un modelo generativo aprende la probabilidad conjunta $p(x,y)$. Entonces, utilizando el Teorema de Bayes, podemos expresar la probabilidad condicional como:
\[p(y|x) = \frac{p(x,y)}{p(x)}.\]Es decir, conociendo $p(x)$—la probabilidad de los datos de entrada—podemos calcular la probabilidad condicional—cumpliendo la tarea de un modelo discriminativo.
Una vez ajustado el modelo generativo, este puede generar nuevos datos $x$ a partir un determinato $y$, donde $y$ puede ser una etiqueta, una imagen, un audio, texto, ruido, etc. Por ejemplo, generar imágenes o videos realistas a partir de un texto descriptivo.
El inicio de los modelos generativos
En el año 2014, los modelos generativos comenzaron a tener un gran impacto en la generación de imágenes. Uno de los papers más citados de la última década es Generative Adversarial Networks (GANs), propuesto por Ian Goodfellow et al. Este modelo utiliza una técnica basada en la competencia entre dos redes neuronales: el generador y el discriminador. El Generador es el modelo que genera las imágenes, mientras que el Discriminador es el modelo que intenta distinguir entre imágenes reales y sintéticas (generadas por el Generador).
Un año antes se había presentado el modelo Variational Autoencoders (VAEs) por Diederik P. Kingma y Max Welling. Este modelo consta de un Encoder y un Decoder. El Encoder mapea los datos de entrada a un espacio latente, mientras que el Decode* mapea los vectores latentes a datos sintéticos—similares a los datos de entrada. Una VAE aproxima la distribución de los vectores latentes a una distribución normal, para luego utilizar muestras de esta distribución y generar nuevos datos. Las GANs y las VAEs, demostraron ser capaces de generar imágenes similares a los datos de entrada a partir de vectores de ruido, sin embargo, los resultados todavía no tenían un realismo aceptable.
En el 2018 se presentó el modelo BigGAN, un modelo que fue capaz de generar imágenes de diversas categorías con una calidad de imagen sin precedentes. En el paper se demuestra que las GANs pueden ser escaladas para generar imágenes de alta resolución. El requisito era simple, incrementar la cantidad de parámetros y la capacidad de cómputo en cada iteración. Ese mismo año también se presentó el modelo StyleGAN—otra GAN a gran escala. Este modelo además de generar imágenes en alta resolución tenía la capacidad de controlar el estilo de las imágenes generadas mediante la manipulación de las variables latentes. Las GANs fueron el estado del arte en la generación de imágenes realistas durante un buen tiempo. Sin embargo, en el año 2020 su título fue desafiado por los Diffusion Models.
Normalizing Flows
En paralelo a las GANs, otro modelo generativo, llamado Normalizing Flow, fue ganando popularidad. Este modelo es conocido como y fue presentado por Laurent Dinh, David Krueger, y Yoshua Bengio en un paper. Este modelo se utiliza para aprender la transformación de una distribución de probabilidad compleja a una distribución simple.
La idea es mapear la distribución de probabilidad de los datos de entrada a una distribución normal. Sin embargo, esta transformación debe ser invertible, es decir, debe ser posible también mapear de la distribución normal a la distribución de los datos de entrada. Entonces, una vez ajustado el modelo, se puede obtener una muestra de la distribución normal y mapearla a la distribución de los datos de entrada, generando nuevos datos sintéticos.
De manera formal, el modelo se define con una variable de entrada $\mathbf{x}\sim p(\mathbf{x})$, una distribución de probabilidad normal $p(\mathbf{z})$ de una variable latente $\mathbf{z}$, y una función biyectiva $f: \mathbf{x}\rightarrow \mathbf{z}$. Recordemos que una función biyectiva es una función que es tanto inyectiva como sobreyectiva. Es decir, cada elemento de la variable de entrada se mapea a un único elemento de la variable de salida, y cada elemento de la variable de salida tiene un único elemento de la variable de entrada. Por consiguiente, la función $f$ debe ser invertible, es decir $f^{-1}: \mathbf{z}\rightarrow \mathbf{x}$.
 |
|---|
| Figura 2. Imagen extraída del paper Density Estimation Using Real NVP. |
El entrenamiento del modelo se realiza a través del Maximum Likelihood. Este método consiste en la predicción de los parámetros con el objetivo de maximizar la probabilidad de los datos observados. En el caso de los Normalizing Flows, se busca maximizar una aproximación de la probabilidad de los datos de entrada $p_\theta(\mathbf{x})$. Sin embargo, utilizando el cambio de variable, la probabilidad de los datos de entrada se puede expresar como:
\[p_\theta(\mathbf{x}) = p_\theta(\mathbf{z})\left|\frac{\partial \mathbf{z}(\mathbf{x})}{\partial \mathbf{x}}\right|=p_\theta(\mathbf{z})\left|\det\left(\frac{\partial f(\mathbf{x})}{\partial \mathbf{x}}\right)\right|,\]donde $\theta$ representa los parámetros de la red neuronal invertible $f$.
Se realizaron mejoras al modelo original, como el RealNVP, un modelo que utiliza transformaciones afines para aprender la función $f$ y además la técnica de multi-scale para mejorar la calidad de las muestras generadas. Otro modelo es Glow, el cual propone una convolución invertible dentro de la arquitectura de los Normalizing Flows, logrando generar imágenes de rostros realistas en alta resolución.
Una de las ventajas de utilizar los Normalizing Flows en comparación con las GANs es que permitener un mejor manipulación de la información semántica de las imágenes generadas. Dado que la transformación es invertible, se puede manipular las variables latentes y observar el efecto en los datos de entrada. Por ejemplo, se puede introducir ciertas características en la imagen generada manipulando las variables latentes en la dirección de interés. Esta carácteristica la hace útil en la resolución de Problemas Inversos (Chávez, 2022), donde se busca encontrar la distribución de las variables latentes que generaron los datos observados.
Diffusion Models
Un Diffusion Model es un modelo generativo que utiliza tres etapas para generar datos sintéticos. La primera etapa consistie en destruir la imagen original de manera gradual. El modelo agrega pequeñas cantidades de ruido a la imagen original hasta destruir la información por completo. Este proceso se conoce como proceso de difusión.
 |
|---|
| Figura 3. Imagen extraída de un tutorial impartido en el CVPR 2022. |
La segunda etapa consiste en entrenar una red neuronal para reconstruir la imagen original a partir de las versiones con ruido de la imagen original. Para ello, la red es entrenada para predecir los distintos ruidos aleatorios que se le agregaron a la imagen original hasta convertirla en ruido. Finalmente, la última etapa consiste en predecir el ruido en cada en cada etapa de la transformación. De esta manera, partiendo desde ruido puro, poco a poco se va construyendo una imagen realista.
Supongamos que la imagen original es $x_0$. El proceso de difusión genera una secuencia de imágenes con ruido $x_1, x_2, x_3, \ldots, x_T$. Donde una imagen $x_{t}$ se genera a partir de la imagen $x_{t-1}$ y el ruido aleatorio $\epsilon$ de la siguiente manera:
\[x_{t} = x_{t-1} \cdot \sqrt{1 - \beta_t} + \beta_t \cdot \epsilon\]Es decir, $x_{t}$ tendrá más ruido que $x_{t-1}$. En cada iteración $t$, $\beta_t$ se incrementa en pequeñas cantidades desde un valor $\beta_1=10^{-4}$ hasta el valor de $\beta_T=0.02$ (ver el paper original para más detalle). Note que $ x_{t-1} \cdot \sqrt{1 - \beta_t}$ contiene la información de la imagen original, mientras que $\beta_t \cdot \epsilon$ contiene el ruido aleatorio—usualmente ruido gaussiano. Entonces, en cada iteración, la información de la imagen original se va destruyendo poco a poco.
Entrenamiento
El objetivo es predecir el ruido $\epsilon$ que se le agregó a la imagen $x_{t-1}$ para obtener $x_t$. El entrenamiento se realiza para distintas versiones de la imagen con ruido, es decir, para distintos valores de $t$.
Para el entrenamiento se utiliza una red neuronal $\psi$ que toma como entrada la imagen con ruido $x_t$ y la iteración $t$. El objetivo ahora es que aa salida de $\psi$ sea igual al ruido $\epsilon$:
\[||\epsilon-\psi(x_t, t)||\]En la práctica, se minimiza este error para un bloque de imágenes con ruido:
\[\mathbb{E}_{x_t,t,\epsilon}||\epsilon-\psi(x_t, t)||\]Para obtener $x_t$ a partir de $x_0$, se puede realizar una aproximación, de tal modo que no sea necesario calcular todas las imágenes intermedias $x_1, x_2, \ldots, x_{t-1}$. Esto permite generar cualquier versión de la imagen con ruido $x_t$ de manera rápida.
Generación de muestras sintéticas
Una vez que el modelo de difusión ha aprendido a predecir $\epsilon$ a partir de una imagen con ruido $x_t$, ahora ya es capaz de generar una imagen. El proceso de generación de una imagen empieza con $x_T$—ruido puro—y el valor de $T$. El modelo captura estos dos valores como entrada para predecir el ruido $\hat{\epsilon}$:
\[\hat{\epsilon}=\psi(x_T, T)\]Podemos considerar $\hat{\epsilon}$ como el ruido que se le agregó a la imagen $x_{T-1}$ para obtener la imagen con ruido $x_T$. Con lo cual, si quitamos el ruido $\hat{\epsilon}$ de $x_T$ obtenemos $x_{T-1}$—una versión con menos ruido. Poco a poco el modelo de difusión ira sustrayendo ruido y agregando información semántica. Al finalizar este proceso el modelo es capaz de generar una imagen $x_0$—realista y semánticamente significativa con respecto a los datos de entrenamiento.
Latent Diffusion Models
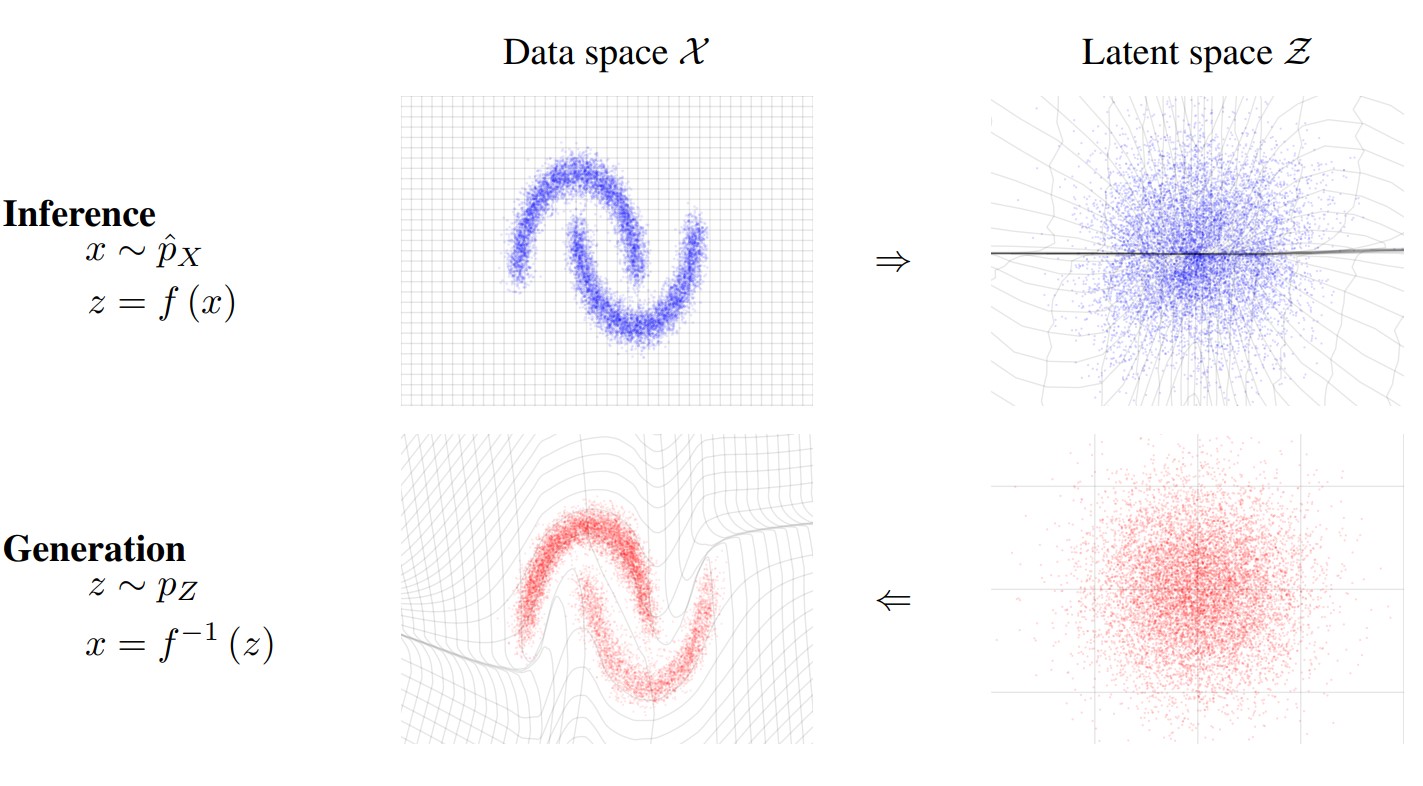
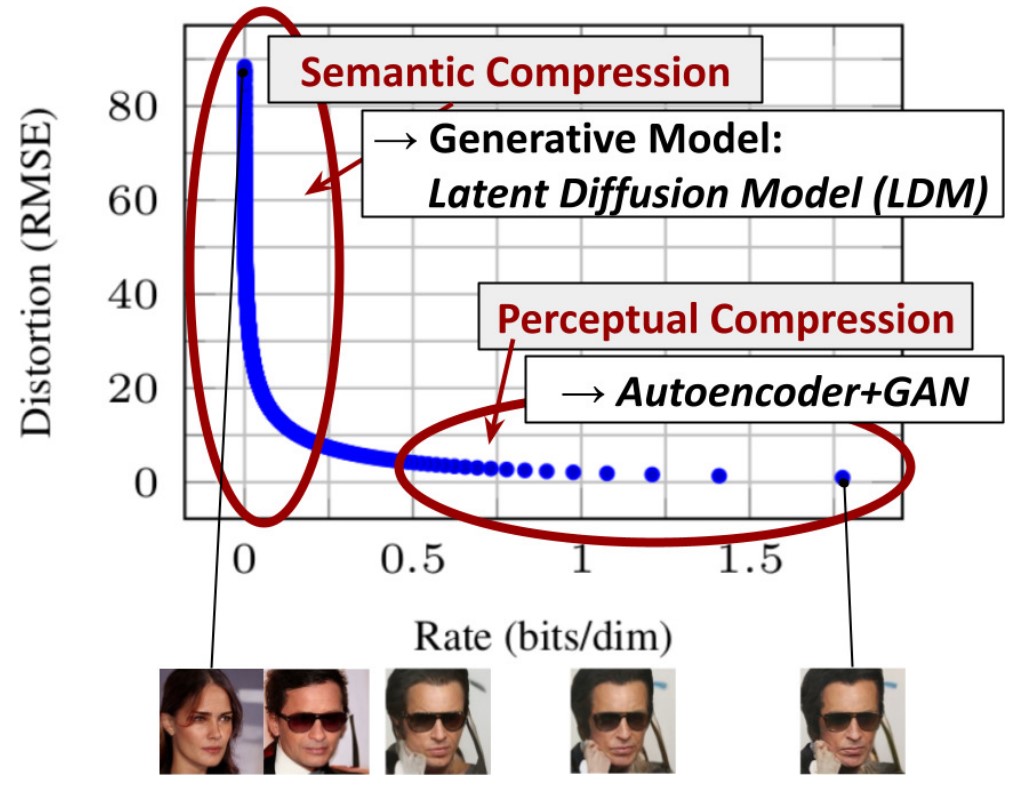
En el año 2020, un artículo demostró que los modelos de difusión eran capaces de generar imágenes realistas. Desde entonces, el modelo ha tenido varias mejoras. Originalmente, el modelo operaba en el dominio de las imágenes, lo cual puede ser costoso si las imágenes están en alta resolución.
Un Latent Diffusion Model (LDM) primero codifica la imagen en un espacio latente de menor dimensión, comprimiendo la imagen de manera espacial. Este proceso se realiza mediante el entrenamiento de una VAE.
 |
|---|
| Figura 4. Imagen extraída del paper High-Resolution Image Synthesis with Latent Diffusion Models. |
Una vez entrenada la VAE, el modelo de difusión opera en el espacio latente. Reduciendo el costo computacional durante el entrenamiento y la generación de imágenes. Este concepto surge de la idea de que el aprendizaje de la distribución de los datos puede dividirse en dos etapas.
La primera etapa consiste en la compresión de la información de las imágenes, eliminando la redundancia y detalles de alta frecuencia. Mientras que la segunda etapa consiste en aprender la composición semantica de las imágenes. De este modo el encoder de una VAE provee una representación en una dimensionalidad menor de la imagen original.
Dall-E 2
Uno de los tencologías más utilizadas recientemente es la generación de imágenes a partir de texto. Este tipo de tarea es conocida como text-to-image y ha sido estudiada desde hace mucho años. En el 2016, un paper (Reed et al.) propuso una variación del modelo GAN, capaz de generar imágenes realistas a partir de texto. Con el pasar de años, los investigadores han intentado proponer diversos modelos con el proposito de generar imágenes cada vez más realistas. Sin embargo, en el año 2022, OpenAI llevaría esta tarea a otro nivel con el modelo Dall-E 2.
 |
|---|
| Figura 4. Imagen extraída del paper Hierarchical Text-Conditional Image Generation with CLIP Latents. |
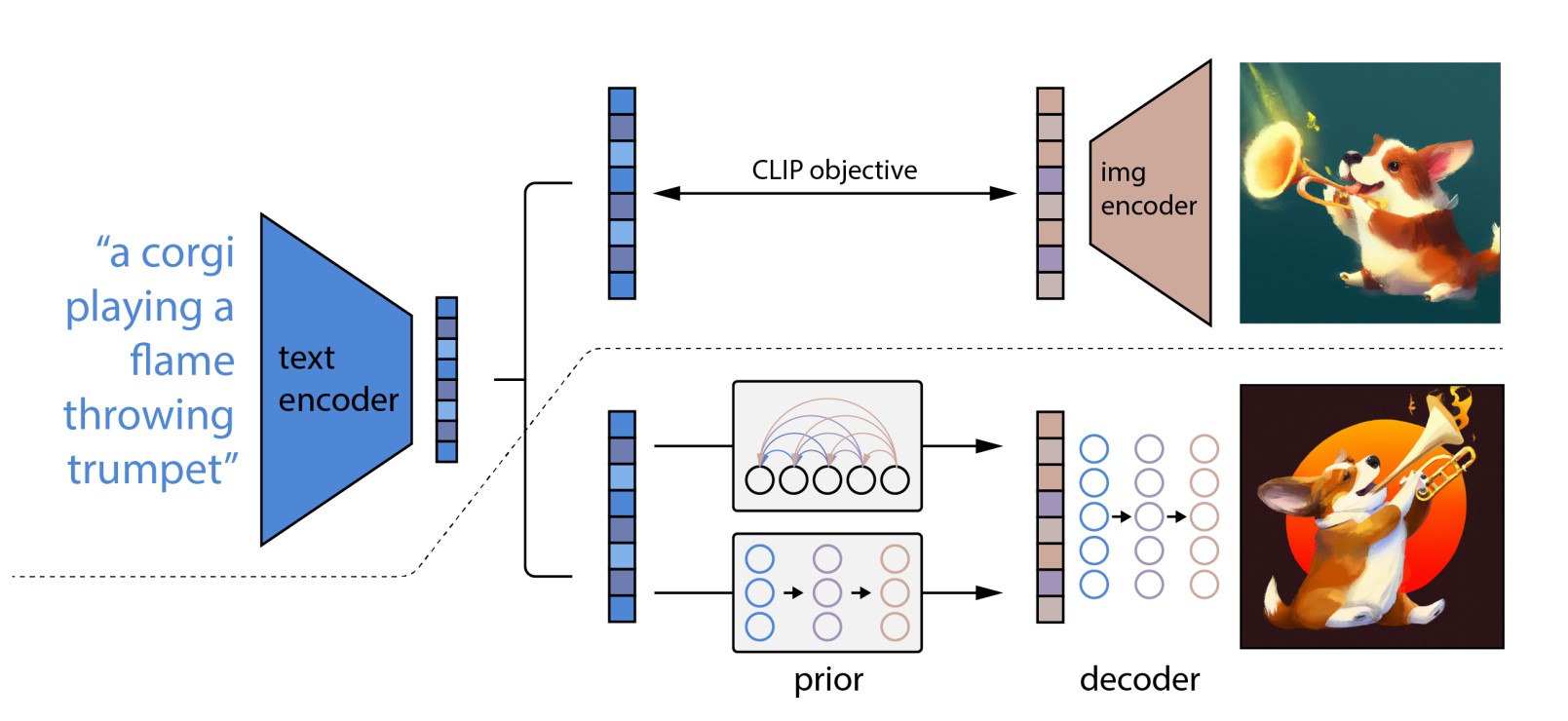
El modelo utiliza una arquitectura llamada CLIP. CLIP utiliza una técnica simple pero eficiente para relacionar texto con imágenes. Dada una imagen y su descripción textual, el modelo CLIP aprende a generar un vector para representar el texto y otro vector representar la imagen. Luego, utiliza la función de similitud coseno para relacionar ambos vectores.
En Dall-E 2, el modelo CLIP es muy útil porque permite relacionar la instrución (prompt) con la imagen resultante. El proceso de entrenamiento empieza con el Text-Encoder, el cual mapea la instrucción a un vector, a este vector le llamaremos el text-embedding. Luego, el modelo Prior mapea el text-embeeding a su respectivo image-embedding, el cual debería capturar la información semántica de la instrucción. Finalmente, el Image-Decoder genera la respectiva imagen a partir del image-embedding y el texto.En los experimentos realizados por OpenAI, se demostró que un Diffusion Model era el que obtenía un mejor rendimiento para el modelo Prior y para el Image-Decoder.
Luego, para determinar si la imagen sintética resultante es realista y es coherente con la instrucción, se utiliza el modelo CLIP. Este evalua la similitud entre la imagen generada y la instrucción de entrada. Si la similitud es alta, entonces la imagen generada es coherente con la instrucción. Entonces, el objetivo es maximizar esta similitud.
El modelo también permite la manipulación de la imagen generada. Dado que el modelo CLIP es capaz de relacionar texto con imágenes, se puede codificar la imagen generada original y obtener sus respectivos embeddings. Luego, se utiliza el Image-Decoder para generar una nueva imagen a partir de estos embeddings—logrando obtener múltiples variantes de la imagen original generada.
Diffusion Transformers
Originalmente, los Diffusion Models utilizaban una U-Net como arquitectura para el procesar la imagen de entrada. Sin embargo, un artículo propuso utilizar un Visual Transformer o ViT en su lugar. Un ViT es una arquitectura procesa la imagen de entrada por patches, los cuales tienen una dimensión fija—usualmente $16\times 16$. Cada patch es transformado a un vector o embedding.
 |
|---|
| Figura 5. Algunas muestras generas por el Diffusion Transformer. |
Una vez obtenidos los embeddings de una imagen, se les agrega el Positional Encoding, el cual inyecta información de la posición espacial de los patches. Llegado a este punto, los embeddings son procesados por un Transformer, el cual es capaz de capturar la relación entre los patches de la imagen. Adicionalmente, cada bloque del Diffusion Transformer puede ser alimentado con información de la instrucción de entrada, como la etiqueta de la imagen.
La ventaja de utilizar un Visual Transformer en lugar de una U-Net es la escalabilidad. El árticulo logra desmostrar una fuerte correlación entre el tamaño del modelo y la calidad de las imágenes generadas. Por lo tanto, un modelo más grande es capaz de generar imágenes de mayor calidad. En el futuro, el modelo DiT ha sido utilizo en modelos como Sora, un generador de videos realistas a partir de un texto descriptivo.